

冰橙API文档地址:https://apifox.com/apidoc/shared-52fb41cb-0e62-4e34-b06d-f9334d7a0502/api-106414419
冰橙AI助手体验地址:https://yewu.bcwhkj.cn
9 月 21 号 OpenAI 在官网上线了 DALL·E 3 的介绍页面,它是一款新的文生图模型,可以根据文本提示词生成各种风格的高质量图像。DALL·E 3 的上一代是去年 4 月份推出的 DALL·E 2,出现时同样因为强大的图像生成能力引起过广泛关注。时隔一年半,新推的 DALL·E 3 有哪些方面的提升?与 Midjourney、Stable Diffusion 等 AI 绘画工具相比又有哪些不同?今天就带大家一起了解。

一、DALL·E 3 的特点
DALL·E 3 介绍页面: https://openai.com/dall-e-3
据官方介绍,DALL·E 3 可以生成完全符合提示词的图像,并能理解更多的细微差别和细节,让用户能轻松地根据自己的想法生成准确的图像。下面是官方给出的对比图,在同一组提示词下,DALL·E 3 在图像质量和细节呈现上的表现比 DALL·E 2 更好。
用 DALL·E 3 官网图像的提示词在 midjourney v5.2 和 Stable Diffusion XL 1.0 中生成了几组图像,通过对比可以看出 DALL·E 3 能很好地理解“治疗师,一个勺子”“闭着眼睛高兴地咬了几口”这样的自然语言,并准确呈现出对应的形象细节,还能正确地生成“I just feel so empty inside”这样的文本内容,而 Midjourney 和 Stable Diffusion 还无法达到同样的效果。
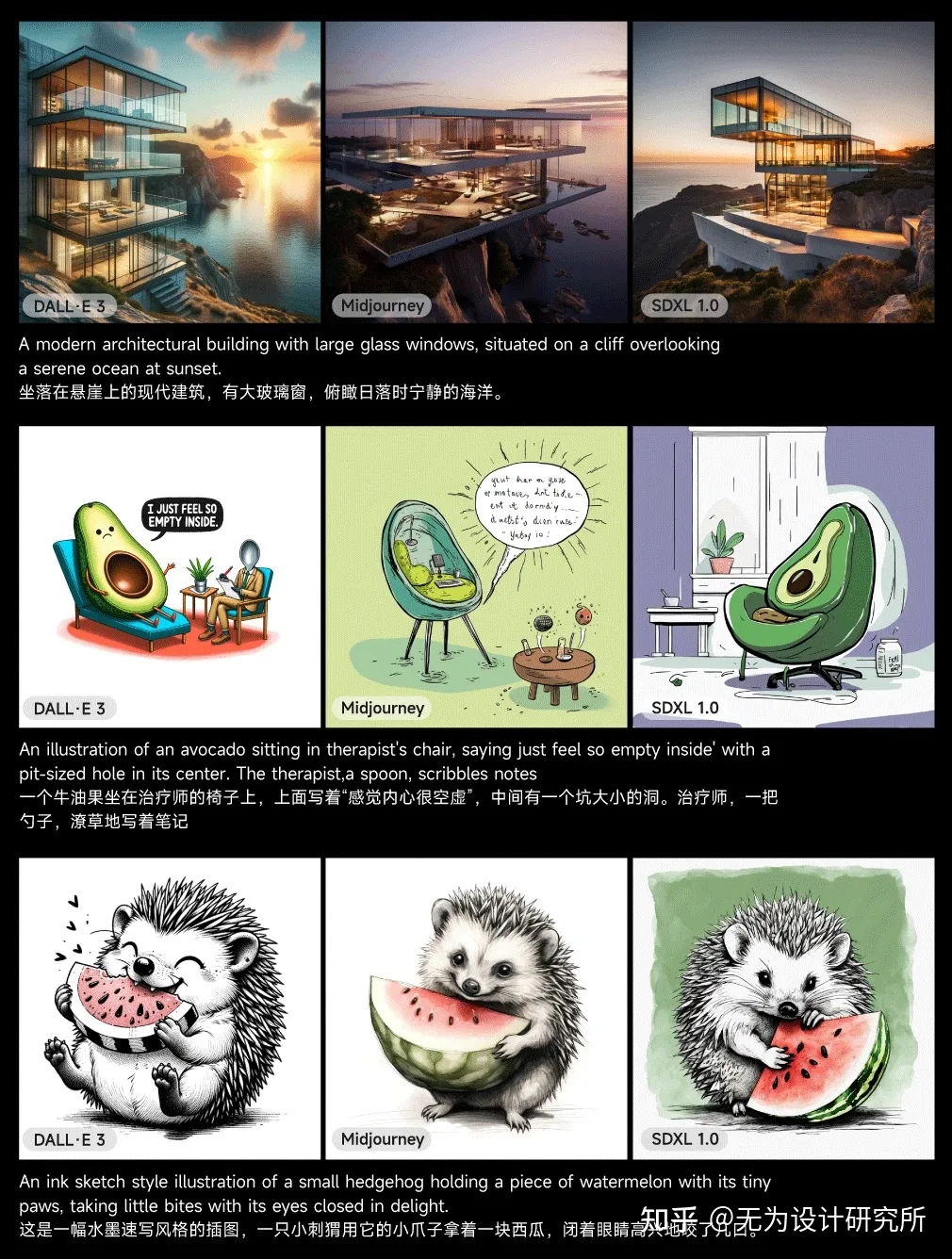
在处理更长更复杂的提示词时,DALL·E 3 可以在画面中完整呈现提示词中的各类元素和特征,比如海鸥、绿光、旋转的云、带有图案的地毯,而 Midjourney 和 Stable Diffusion 则会遗漏掉部分细节特征。

除了强大的图像生成能力,DALL·E 3 另一个备受瞩目的点是它可以配合 ChatGPT 使用。
官网上有一段 DALL·E 3 in ChatGPT 的演示视频,视频中当用户提出一段想法时,ChatGPT 会自动生成非常详细的提示词,并调用 DALL·E 3 生成的准确图像;用户还可以直接发送文字指示,让 ChatGPT 对图像进行修改。整个过程中,ChatGPT 能提供无限的灵感和创意,DALL·E 3 可以快速将用户的想法具象化呈现,流畅的配合让一个故事的诞生变得轻松自然,这种新的图像生成体验更是让人眼前一亮。
在 DALL·E 3 in ChatGPT 的演示视频,来源 OpenAI 官网
官网上显示 DALL·E 3 生成的图像可以直接商用,同时 OpenAI 在相关版权政策上也有新的变化,包括 DALL·E 3 会拒绝生成在世艺术家风格的图像,艺术创作者可以选择退出 OpenAI 未来图像生成模型的训练。此外 DALL·E 3 还提升了其图像生成的安全性,比如拒绝生成公众人物图像,限制暴力、成人或仇恨内容的生成,以及弱化生成图像中潜在的偏见性。

DALL·E 3 的吸引力是毋庸置疑的,但想要用上它可能并不容易。毕竟能否成功注册一个 OpenAI 账号对我们来说可能都是一个大问题,而且之前也出现账号注册成功后又被封禁的情况,从这点来看 Midjourney 和开源的 Stable Diffusion 就友好的多了。
在 DALL·E 3 in ChatGPT 的演示视频中, 虽然展示了文生图、按提示修改图像等操作,但图像处理功能并没有更多体现。目前 Midjourney 和 Stable Diffusion 的功能都非常完善,可以实现自定义画幅、图生图、高清放大、局部重绘、外绘拓展等操作,这些功能未来在 DALL·E 3 中能否实现,以及如何通过 ChatGPT 实现都还是未知数。

从另一方面来说,DALL·E 3 的出现表明文生图技术又有了新的进步:AI 可以更好地理解自然语言、准确地且完整地呈现画面细节和元素之间的关系,以及生成正确的文本内容,这意味着 Midjourney 和 Stable Diffusion 等 AI 绘画工具的图像生成能力在未来可能也会有同样的提升。同时 DALL·E 3 in ChatGPT 也会进一步促进多模态输出模式的发展,未来肯定会有更多 AI 聊天工具也支持生成图像。

请立即点击咨询我们,我们会详细为你一一解答你心中的疑难。点击立即沟通

 在线QQ客服【点击对话】
在线QQ客服【点击对话】